
[AI 미션클리어] 8차시 – Teachable Machine으로 물체 구분하는 모델 만들기
1.데이터 수집 실습

각도와 카메라의 거리를 다양하게 하여 약 180개 정도의 이미지 데이터를 수집했습니다.
2.모델 학습시키기
에포크 50, 배치 크기 16으로 모델을 학습시켰습니다
에포크 2로 모델을 학습시켰을때의 에포크별 정확도와 손실입니다.
3.test loss와 loss
고급 설정의 어휘를 보면 학슴 샘플과 테스트 샘플을 확인할 수 있다. 학습 샘플은 지난 시간에 배운 트레이닝셋, 테스트샘플은 테스트셋이다.
트레이닝 셋으로 학습을 시키고 그 다음에 라벨이 붙지 않은 걸 가지고 테스트한다.
내가 모은 교과서, 필통, 파우치의 이미지 샘플들이 트레이닝 셋과 테스트 셋으로 나뉘는 것이다.
교과서 이미지 샘플의 182개 중 85%는 트레이닝 셋, 15%는 테스트 셋이 되는 것이다. 필통과 파우치 샘플도 마찬가지로 각각 85%와 15%로 나뉘게 된다.
그래서 당연히 에포크를 돌기 전에는 모든 데이터에 대해 손실이 굉장히 큰 것이다. 하지만 그 물질의 특징이 확실하기 때문에 test loss는 갈수록 절반의 수치로 loss가 떨어진다.
test loss가 아닌 그냥 loss는 더 급격하게 떨어지는 걸 확인할 수 있다!
4.혼동 행렬 확인하기

Y축 : Class
우리가 설정한 class
=> 우리가 분류해놓은 카테고리
X축: Prediction예측해서 분류할 수 있는 항목테스트 셋에 대한 자료들(label, prediction, count)
그림처럼 테스트 데이터셋이 전부 다 왔다라는 건 학습이 잘됐다는 것이다. 181의 15%는 27.15로 학습이 상당히 잘 된 것이다!
현재 0인 칸에 1이나 다른 숫자들이 오면 인식률이 떨어지는 모델이라고 보면 된다. 교과서인데 파우치로 인식했다는 등 어디서 잘못 됐는지를 확인할 수 있다.
즉 대각에만 테스트 데이터 셋들이 있어야 학습이 잘 된 거라고 볼 수 있는 것이다
5. 인식률 안 좋은 모델 확인하기

눈을 뜨고 있는 이미지, 윙크하고 있는 이미지 데이터 61개씩 수집

에포크 2, 배치 크기 128로 모델을 학습시킨 결과 성능이 정말 좋지 않았음

정확도도 0.5에 머물러 있고
test loss, loss 모두 손실이 엄청 크다는 것을 확인할 수 있다

대각선으로 테스트 데이터셋이 모여있지 않다! 저 행렬을 분석해보면 wink로 분류되어야할 데이터가 open eyes로 분류된다는 것이다.
6. 성능 향상/평가하는 법
-향상
1. 데이터 수집량 늘리기
2. 데이터 정제하기
3. 에포크, 배치 사이즈 적절히 조절하기
-평가
1. 정확도 함수 그래프
2. 손실 함수 그래프
3. 혼동 행렬
6.모델 내보내기


손을 들고 있을 때와 아닐 때를 구분하는 모델을 만들어 모델 내보내기 연습~~
상단에 모델 내보내기 아이콘을 클릭하고
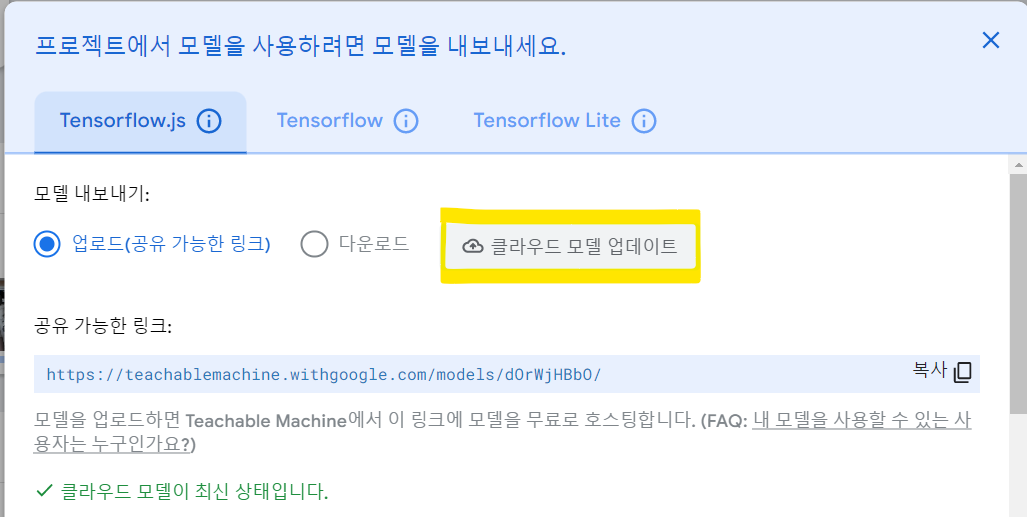
클라우드 모델 업데이트를 누르면 링크가 생성된다
저 링크로 들어가면

모델을 사용하여 추론할 수 있는 페이지로 연결된다.
또는

js 코드를 복사하여 html 파일에 붙여넣을 수 있다.
